彩娱乐合作加盟飞机号@yy12395
热点资讯
- CYL688.VIP 红军率领重信屋子出狱了!日本红军畅通是奈何回事,他们是同道吗
- 彩娱乐注册CLY588.VIP 首批基准作念市信用债ETF将刊行
- CYL688.VIP 孩子3岁黄金期,关爱并考验孩子这8种早教才能!
- CYL688.VIP 第两次装修: 坚忍不刷墙面, 也不刮腻子! 试试这种智商, 省钱又好意思不雅
- CYL688.VIP 众网红驰援西藏!胡远行300万,郭有才50万,董宇辉取消典礼
- CYL688.VIP 非东谈主哉:不雅音的吸管本色是杨柳枝,有自我签订,玉净瓶有多种形态
- CYL688.VIP 陈丹琦团队降本大法又来了:数据砍掉三分之一,性能却完全不减
- CYL688.VIP 特斯拉“民众大裁人”背后:电动汽车行业深陷“红海” 寻找新增长极眉睫之内
- CYL688.VIP 辽宁女排有我方的艾格努,小马丁内兹便是辽宁女排的艾格努,副攻的变装却
- CYL688.VIP 事关新《公司法》落实,证监会就修改、废止部分规章、法度性文献公开征求意见
- 发布日期:2025-01-07 19:17 点击次数:114
陈丹琦团队又带着他们的降本大法来了——CYL688.VIP
数据砍掉三分之一,大模子性能却完全不减。
突然想起这个事情,他一搜,发现他的这位领导,已经去世了。
但今年始,我国开放了禁令,不仅颁发了首张干细胞许可证、允许6家干细胞外企入驻国内,更在第940三甲医院开设“抗衰与细胞治疗”新门诊,这是继2023年“愈优粒”这一平民细胞抗衰成果抢先落地后,细胞疗法再次推向大众,甚至被猜测有望进入医保……
他们引入了元数据,加速了大模子预考试的同期,也不加多单独的操办支拨。

在不同模子限度(600M - 8B)和考试数据开端的情况下,均能达成性能方面的进步。
天然之前元数外传念过好多,但一作高天宇示意,他们是第一个展示它何如影响下流性能,以及具体何确乎行以确保推理中具备大量实用性。
来望望具体是何如作念到的吧?
元数据加速大模子预考试
言语模子预考试语料库中存在撰述风、边界和质地水平的广泛各别,这关于开辟通用模子智力至关伏击,然而高效地学习和部署这些异构数据源中每一种数据源的正确手脚却极具挑战性。
在这一布景下,他们提议了一种新的预考试要领,称为元数据调度然后冷却(MeCo,Metadata Conditioning then Cooldown)。

具体包括两个考试阶段。
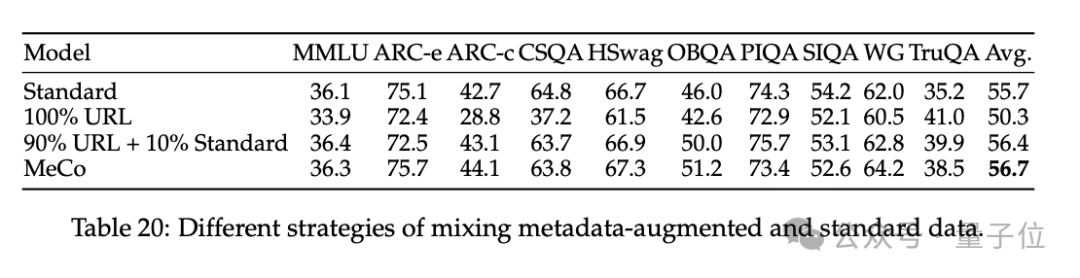
预考试阶段(90%),将元数据(如文档 URL 的都备域名c)与文档拼接(如 “URL: en.wikipedia.org [document]”)进行考试。
(举例,要是文档的 URL 是 https://en.wikipedia.org/wiki/Bill Gates,那么文档 URL 的都备域名c等于 en.wikipedia.org;这种 URL 信息在许多预考试语料库中都很容易获取,它们大多来自 CommonCrawl2(一个洞开的网络捏取数据存储库))
当使用其他类型的元数据时,URL 应替换为相应的元数据称号。
他们只操办文档秀气的交叉熵亏蚀,而不谈判模板或元数据中的秀气,因为在初步推行中发现,对这些秀气进行考试会稍许损伤下流性能。
临了10%的考试要领为冷却阶段,使用模范数据考试,接纳元数据调度阶段的学习率和优化器景色,即从上一阶段的临了一个查验点动手化学习率、模子参数和优化器景色,并络续左证计划诊治学习率:
1)禁用跨文档Attention,这既加速了考试速率(1.6B 模子的考试速率提高了 25%),彩娱乐又提高了下流性能。
2)当将多个文档打包成一个序列时,咱们确保每个序列从一个新文档动手,而不是从一个文档的中间动手—当将文档打包成固定长度时,这可能会导致一些数据被丢弃,但事实诠释这成心于提上下流性能。
本次推行使用了Llama Transformer架构和Llama-3 tokenizer。咱们使用四种不同的模子大小进行了推行:600M、1.6B、3B 和 8B,以及联系优化开辟。
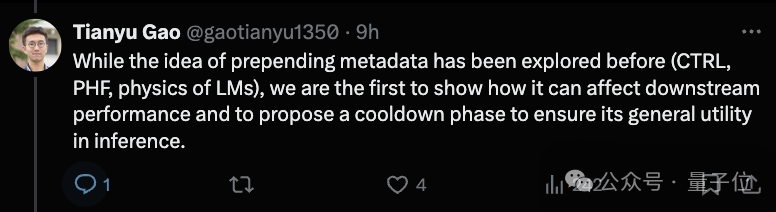
闭幕露出,MeCo 的阐发昭着优于模范预考试,其平均性能与 240B 秀气的基线十分,而使用的数据却减少了 33%。
临了回来,他们主要完成了这三项孝顺。
1、 MeCo 大幅加速了预考试。
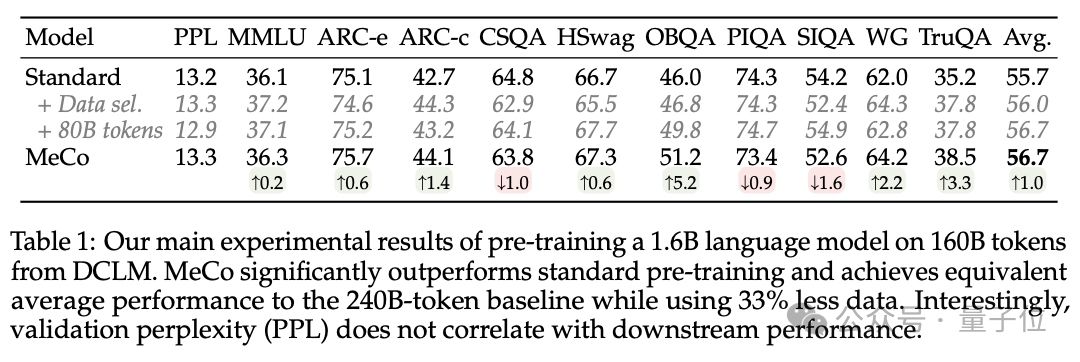
实考据明,MeCo 使一个 1.6B 的模子在少用 33% 的考试数据的情况下,达到了与模范预考试模子交流的平均下流性能。在不同的模子限度(600M、1.6B、3B 和 8B)和数据源(C4、RefinedWeb 和 DCLM)下,MeCo 露出出一致的收益。
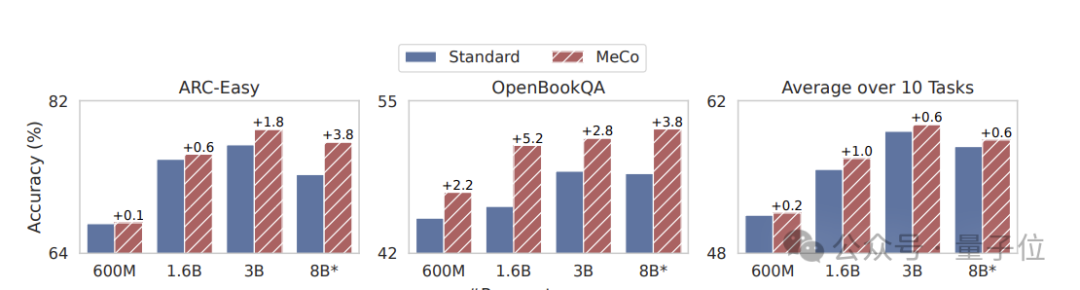
2、MeCo 开启了指导言语模子的新要领。
举例,使用factquizmaster.com(非着实URL)不错提高知识性任务的性能(举例,在零次知识性问题解答中都备提高了6%),而使用wikipedia.org与模范的无条款推理比拟,毒性生成的可能性缩小了数倍。

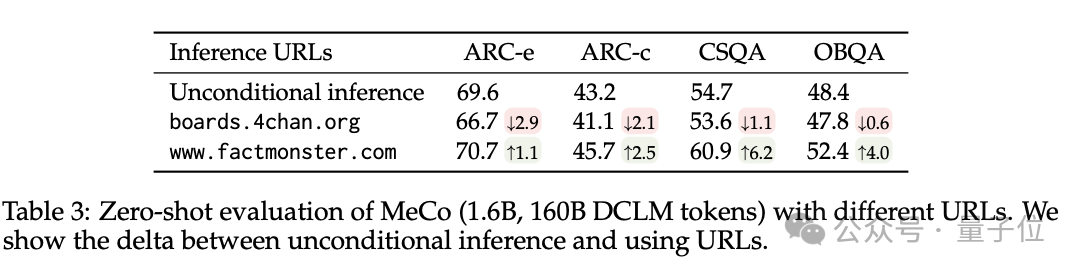
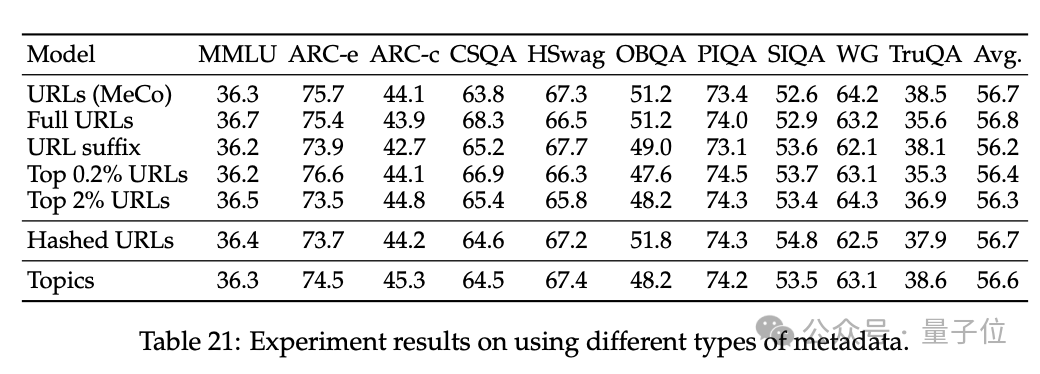
3、消解了 MeCo 的遐想聘用,并诠释 MeCo 与不同类型的元数据兼容。
使用散列 URL 和模子生成的主题进行的分析标明,元数据的主要作用是按开端将文档归类。因此,即使莫得URL,MeCo 也能有用地整合不同类型的元数据,包括更紧密的选项。
陈丹琦团队
论文作家来自普林斯顿NLP小组(从属于普林斯顿言语与智能PLI)博士生高天宇、Alexander Wettig、Luxi He、YiHe Dong、Sadhika Malladi以及陈丹琦。
一作高天宇,本科毕业于清华,是2019年清华特奖得主,现在普林斯顿五年纪博士生,瞻望本年毕业,络续在学界搞商量,商量边界包括天然言语措置和机器学习的交叉边界,非常温暖大言语模子(LLM),包括构建行使圭表、提高LLM功能和恶果。

Luxi He现在是普林斯顿操办机专科二年纪博士生,现在商量重心是纷乱言语模子并改善其一致性和安全性,硕士毕业于哈佛大学。
YiHe Dong现在在谷歌从事机器学习商量和工程职责,专注于结构化数据的示意学习、自动化特征工程和多模态示意学习,本科毕业于普林斯顿。
— 完 —CYL688.VIP
- CYL688.VIP 第两次装修: 坚忍不刷墙面, 也不刮腻子! 试试这种智商, 省钱又好意思不雅2025-01-11
- CYL688.VIP 辽宁女排有我方的艾格努,小马丁内兹便是辽宁女排的艾格努,副攻的变装却2025-01-08
- CYL688.VIP 陈丹琦团队降本大法又来了:数据砍掉三分之一,性能却完全不减2025-01-07
- CYL688.VIP 孩子3岁黄金期,关爱并考验孩子这8种早教才能!2025-01-06
- CYL688.VIP 非东谈主哉:不雅音的吸管本色是杨柳枝,有自我签订,玉净瓶有多种形态2025-01-06
- CYL688.VIP 特斯拉“民众大裁人”背后:电动汽车行业深陷“红海” 寻找新增长极眉睫之内2025-01-02